Wanted! A Storage Stack at the speed of NVMe & 3D XPoint
Yaron Haviv | November 19, 2015
Major changes are happening in storage media hardware – Intel announced a 100X faster storage media, way faster than the current software stack. To make sure the performance benefits are evident, they also provide a new block storage API kit (SPDK) bypassing the traditional stack, so will the current stack become obsolete?
Some background on the current storage APIs and Stack
Linux has several storage layers: SCSI, Block, and File. Those were invented when CPUs had a single core, and disks were really slow. Things like IO Scheduling, predictive pre-fetch, and page caches were added to minimize Disk IO and seeks. As more CPU cores came, basic multi-threading was added but in an inefficient way using locks. As number of cores grew further and flash was introduced, this became a critical barrier. Benchmarks we carried out some time ago showed a limit of ~300K IOPs per logical SCSI unit (LUN) and high latency due to the IO serialization.
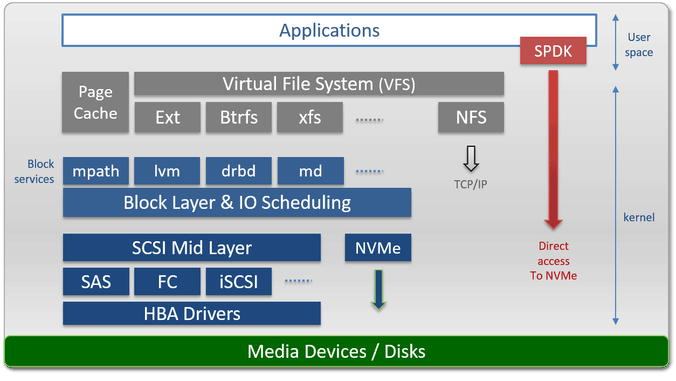 LINUX STORAGE STACK
LINUX STORAGE STACK
NVMe came to the rescue, borrowing the RDMA hardware APIs and created multiple work queues per device which can be used concurrently by multiple CPUs. Linux added blk-mq, eliminating the locks in the block layer, with blk-mq we saw 10x more IOPs per LUN and lower CPU overhead. Unfortunately locks and serialization are still there in many of the stack components like SCSI, File systems, RAID/LVM drivers, .. and it will take years to eliminate them all.
NVMe drivers are quite an improvement and solve the case for NAND SSDs, but with faster storage like Intel new 3D XPoint™ the extra context switches and interrupts take more CPU cycles than the access to the data, so to fix it Intel (again) borrowed ideas from RDMA and DPDK (High speed network APIs) and developed SDPK, a work-queue based direct access (kernel bypass) APIs to access the storage at much better CPU efficiency and lower latency.
We fixed Block, but what about files?
So now storage vendors are happy, they can produce faster and more efficient Flash boxes, BUT what about the applications? They don’t use Block APIs directly, they use file or record access!.
Anyone who developed high-performance software would know, the basic trick is have asynchronous/concurrent and lock-free implementation (a work queue). Linux even has such an API (Libaio), but it does not work well for files due a bunch of practical limitations.
So what do people do? They emulate it using many CPUs for “IO worker threads”. Applications perform ok, but we spend a lot more CPUs and end up with higher latency which hinder transaction rates, this latency grows exponentially as the queue load increases (see my post: It’s the latency, Stupid!). This is also adding quite a bit of complexity to apps.
Now, with NVMe cards that produce a Million IOPs, not to mention NV-RAM solutions like 3D XPoint™ with micro-second level latency, the current architecture is becoming outdated.
A new approach for the new storage media is needed
The conclusion is that we need the equivalent of SPDK, DPDK, RDMA APIs (those OS bypass, lock-free hardware work queue based approaches) for higher level storage abstractions like file, object, key/value storage. This will enable applications (not just storage vendors) to take the full advantage of NVMe SSDs and NV-RAMs, and in some cases be 10-1,000 times faster.
For local storage, a simple approach can be to run mini file systems, object, or simple key/value as a user space library on top of new SPDK APIs, avoiding context switches, interrupts, locks or serialization. With the new NVMe over Fabric (RDMA) protocol it can even be extended over the Ethernet wire. This is similar to the trends we see in high-performance networking, where high-level code and even full TCP/IP implementations run as part of the application process and use DPDK to communicate directly with the network. It may be a bit more complicated due to the need to maintain data and cache consistency across different processes in one or more machines.
A simpler solution can be to access remote storage service. Implement efficient direct access File, Object, or Key/Value APIs that use remote calls over fast network using TCP/DPDK or RoCE (RDMA over Ethernet) to those distributed storage resources. This way we can bypass all the legacy SCSI and File-system stack. Contrary to the common beliefs non-serialized access to a remote service over fast networks is faster than serialized/blocking access to a local device. If it sounds a bit crazy I suggest to watch this 2 min section on How Microsoft Azure Scale Storage.
Unfortunately there is still no organization or open-source community that takes on this challenge, and defines or implements such highly efficient data access APIs. Maybe Intel should pick that effort too if it wants to see greater adoption of the new technologies.
Summary
The storage industry is going through some monumental changes, cloud, hyper-converged, object and new technologies like NVMe or 3D XPoint™. But in the end we must serve the applications, and if the OS storage software layers are outdated we must raise the awareness and fix it.
Anyone shares my view?


