It’s Time for Reinventing Data Services
Yaron Haviv | May 31, 2016
During the last decades, The IT industry have used and cultivated the same storage and data management stack. The problem is, everything around those stacks changed from the ground up — including new storage media, distributed computing, NoSQL, and the cloud.
Combined, those changes make today’s stack exceedingly inefficient — slowing application performance, creating huge operational overhead, and hogging resources. An additional impact of today’s stack is multiple data silos that are each optimized to a single application usage model, and the requirement for data duplication to handle the case when multiple access models are used.
With the application stack now adopting a cloud-native and containerized approach, what we also need are highly efficient cloud-native data services.
The Current Data Stack
Figure 1 shows, in red, the same functionality being repeated in various layers of the stack. This needless repetition leads to inefficiencies. Breaking the stack into many standard layers is not the solution, however, as the lower layers have no insight into what the application was trying to accomplish, leading to potentially even worse performance. The APIs are usually serialized and force the application to call multiple functions to update a single data item, leading to high overhead and data consistency problems. A functional approach to update data elements is being adopted in cloud applications and can solve a lot of chatter.
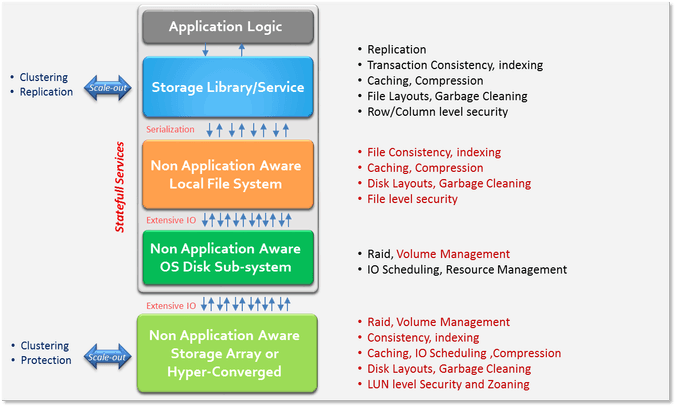
Figure 1: Current Data Stack
In the current model the application state is stored with the application (known as stateful or persistent services). This is incontrast to the cloud-native architecture and leads to deployment and maintenance complexity.
When developing cloud-native apps in the public cloud, data is stored in shared services such as Amazon S3, Kinesis, or DynamoDB. Meanwhile, the application container is stateless, leading to lower cost and easier-to-manage application environments. To save the extra overhead, new data services use direct attached storage and skip the lowest layer (external storage array or hyper-converged storage), but that process eliminates only a small part of the problem.
In the last few years, new types of media – including SSD, NV-Memory solutions, key/value disks, shingled drives – have emerged. Bolting a sector-based disk access API or even a traditional file-system on top of those new media types may not be the correct approach; there are more optimal ways to store a data structure in a specific media, or the media may offload portions of the upper stack. The media API needs to be at a higher level than emulating disk sectors and tracks on elements with no spinning head. A preferred functional yet generic approach would be to store structures of variable data size with an ID (key) that will be used to retrieve that data (also called key/value storage) .
Time for a new stack
The requirements are simple:
- Don’t implement the same functionality in multiple layers
- Enable stateless application containers and a cloud-native approach
- Avoid data silos; store the data in one place that efficiently supports a variety of access models
- Provide secure and shared access to the data from multiple applications and users
- Enable media-specific implementations and hardware offloads
- Simplify deployment and management
An optimal stack has just three layers, as is illustrated in Figure 2: Elastic applications, elastic data services, and a media layer.
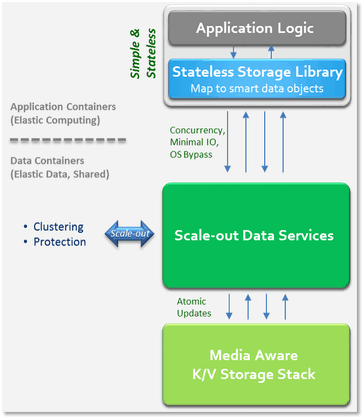
Figure 2: The New Data Stack
- Elastic applications want to persist or retrieve data structures in the forms of objects, files, records, data streams and messages, all of which can be done with existing APIs or protocols mapped to a common data model, and in a stateless way which always commit updates to the backend data services (this will guarantee that apps can easily recover from failures and that multiple apps can share the same data in a consistent fashion).
- The elastic data services expose “data containers” which store and organize data objects serving one or more applications and users. The applications can read, update, search or manipulate data objects, with the data service providing guaranteed data consistency, durability and availability. Security can be enforced at the data layer as well, making certain only designated users or applications access the right data elements. Data services should scale-out efficiently, and potentially can be distributed on a global scale.
- The media layer should store data chunks in the most optimal way for the media, which might include a remote storage system or cloud. Data elements of variable sizes can be assigned unique keys to retrieve the data rather than accessing fixed-size disk sectors. By adding a key/value abstraction, we can implement a media-specific way to store the chunks. For example, when using non-volatile memory one would use pages; with hard drives, one would use disk sectors; and with flash one would use blocks and eliminate redundant flash logical-to-physical mappings and garbage cleaning. The media or remote storage may support certain higher level features such as RAID, compression, deduplication, and more, in which case the data service can skip those features in software and offload it to the hardware.
This article was originally posted on insidebigdata.com
Yaron


