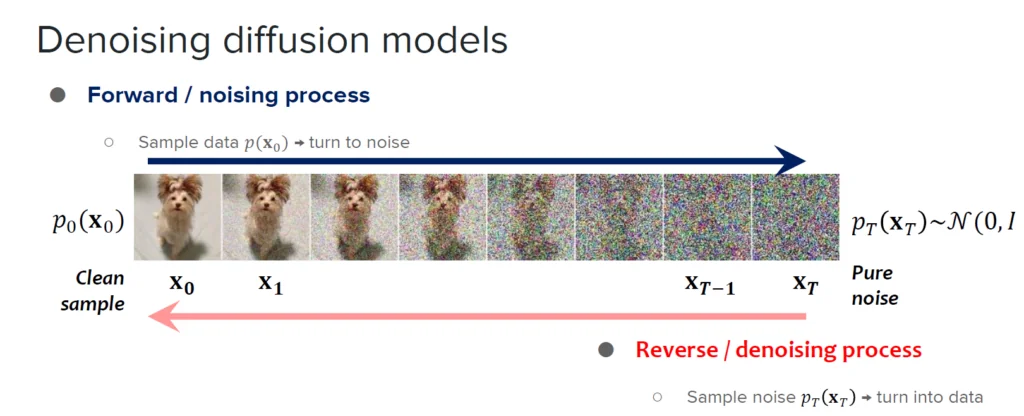
Diffusion models are powerful generative models that are able to produce high-quality, diverse samples of image, audio or text across various domains. This is done based on their training datasets’ visual and statistical properties. The process they follow includes:
Starting with a real data sample.
Corrupting the data by gradually adding Gaussian noise until the data is pure noise.
Reversing the noise-adding process until a coherent, but new, data sample is created.
Diffusion models are versatile and flexible. They can be used for multiple applications, like generating synthetic data, drug discovery, enhancing images, art creation and more. However, they are also computational intensive and require significant resources for both training and generating new samples. MLOps practices can help effectively deploy and manage diffusion models deployment.
Why are Diffusion Models Important?
Diffusion models stand out compared to other generative models due to their exceptional abilities:
Generating quality, high-fidelity and detailed outputs
Allowing for diverse outputs that can be used across different domains, thanks to their flexibility and adaptability
Showcasing stable and predictable training behavior to prevent mode collapse
Reducing the need for adversarial training, thanks to smooth training process
Being easier to understand and use, due to their robust theoretical foundation
How are Diffusion Models Used?
Diffusion models’ unique ability to generate high-quality, new data samples opens up opportunities across industries. Capabilities include:
Image Generation and Editing – Creating digital art, graphic designs and interactive media, as well as image-to-image translation, image editing, image restoration and image enhancement
Video Generation – Filmmaking and animations.
Audio Synthesis – Composing and generating music, speech synthesis and producing realistic soundscapes and voices
These capabilities have a wide range of uses across healthcare, finance, science, automotive, art, gaming, archeology, entertainment, security, VR, e-commerce, fashion, education, advertising and much more. For example:
Simulations – Creating visualizations for training purposes, such as medical simulations, historical recreations, and more to enhance understanding and retention of complex subjects.
Drug Discovery and Material Science – Predicting molecular structures and properties to accelerate the process of drug discovery and material science.
Climate and Weather Modeling – Generating accurate simulations of environmental processes to better understand climate change impacts and improve weather prediction accuracy.
Challenges and Critiques in Diffusion Modeling
Despite their remarkable capabilities, using diffusion models comes with its own set of challenges:
Computational Efficiency – Generating samples from diffusion models involves numerous forward and backward steps, making it significantly slower and more resource-intensive compared to other generative models like GANs.
This results in:
High costs
A high environmental impact
Limited accessibility to smaller organizations
Quality vs. diversity trade-off – Achieving both high-quality outputs and a wide variety of samples from diffusion models is challenging, since the model usually prioritizes either learning detailed representations or a wide range of possible outputs. Improving one aspect can sometimes come at the expense of the other.
Training data bias – Like all AI models, diffusion models are susceptible to biases present in their training data. If the data contains biases, the model’s outputs will likely reflect these biases. This could potentially lead to ethical concerns or unfair outcomes, like deepfakes of misinformation.
Types of Popular Diffusion Models
Basic diffusion models – The foundational variant. It works by gradually adding noise to data and then learning to reverse this process. These models have been applied to a variety of data types, including images, audio, and text.
Denoising diffusion probabilistic models (DDPMs) – Diffusion models that focus on the denoising step. They operate by predicting the noise that has been added to an image (or any other type of data) at each step of the diffusion process, allowing for more controlled and high-fidelity generation.
Conditional diffusion models – An extension of the basic diffusion framework, designed to generate data based on specified conditions or attributes. They are particularly useful for tasks where the output needs to meet certain criteria, such as generating images of a specific object or scenes with particular characteristics.
Text-to-Image diffusion models – A subset of conditional diffusion models. These models are specifically designed to generate images based on textual descriptions. They can create detailed, realistic images from complex textual prompts, opening up new possibilities for creative and practical applications.
Latent diffusion models – Models that apply the diffusion process in a latent space, rather than directly on the data itself. This approach allows for more efficient training and generation processes. This is because operating in a latent space often requires less computational power than working with high-dimensional data directly. Latent diffusion models have shown remarkable results in generating high-quality images and other complex data types.
Guided diffusion models – Models that incorporate additional guidance during the generation process, often in the form of classifier guidance or other mechanisms. This helps steer the output towards desired characteristics. This guidance can significantly improve the model’s ability to generate specific types of outputs, such as images that conform to particular styles or texts that follow a desired narrative.
Audio diffusion models – Models tailored for generating coherent and high-fidelity audio clips. These models can be conditioned on various inputs, such as text or other audio, to produce music, speech, or sound effects.
Stable diffusion models – Models tailored for generating high-quality images efficiently. They transform random noise into detailed images through learned reverse diffusion steps, guided by textual or other forms of input. These models stand out for their robustness and the remarkable fidelity of the images they produce.
Autoregressive models – Models that predict future values based on past values. They regress on themselves, using previous outputs as inputs for prediction. This methodology is widely applied in time series forecasting and sequential data processing.
Diffusion Models and MLOps
MLOps is the methodology of integrating and automating ML and generative models into ML pipelines, to streamline and optimize the lifecycle of ML projects. MLOps can help effectively deploy and manage diffusion models across the pipeline:
Model versioning and experiment tracking – Tracking various versions of the model and the experiments leading to them ensures reproducibility and helps in understanding the impact of different parameters and training data.
Scalability – Diffusion models are resource-intensive. MLOps practices help in scaling these models efficiently to ensure computational resources are optimally used and costs are managed.
Monitoring and maintenance – Once deployed, the performance of diffusion models needs to be continuously monitored to ensure they are generating the desired outputs and not deviating into generating inappropriate or unintended content. MLOps facilitates this ongoing monitoring and the necessary model updates.
Ethical considerations – The deployment of powerful generative models like diffusion models raises ethical considerations, including the potential for generating misleading or harmful content. MLOps practices can include ethical guidelines and checkpoints to ensure responsible use.