Announcing Iguazio Version 3.0: Breaking the Silos for Faster Deployment
Gilad Shaham | May 11, 2021
Overview
We’re delighted to announce the release of the Iguazio Data Science Platform version 3.0. Data Engineers and Data Scientists can now deploy their data pipelines and models to production faster than ever with features that break down silos between Data Scientists, Data Engineers and ML Engineers and give you more deployment options . The development experience has been improved, offering better visibility of the artifacts and greater freedom of choice to develop with your IDE of choice. Finally, this version also includes new options to help optimize costs. As part of Iguazio’s commitment to the open-source community, we have also updated MLRun – the open-source MLOps orchestration framework. See https://www.mlrun.org/ for more details.

Version Highlights:
Collaborate between functions with shared project visibility
Working in silos is still one of the main pain points we hear from customers and the industry at large. The approach of ‘throwing it over the wall’ gets a lot of deserved flak in software development, but ML teams are still lacking effective collaboration systems. In this 3.0 update, we’ve added features to help Data Scientists and Data Engineers exchange information and collaborate in a much more streamlined way.
Each project now has a dashboard view, showing the status of the project, including the feature-sets, models, jobs, and functions that are part of this project. The whole team can review and work together on different projects, starting from data integration, through model development all the way to production deployment and governance.
With MLRun, running your code inside a project requires a single line of configuration code. Simply call:
mlrun.set_environment(project=project_name)
From that point forward, any function you run using MLRun will be in the current project context, all experiments will be tracked as part of that project, and any features or models you deploy will be part of the project.
Rapid Deployment of Real-Time Pipelines
Most of the complexities in machine learning arise from the data. Data transformation and processing are particularly laborious and challenging, but they are critical steps that most models require. That’s why we consider the entire pipeline—including data transformation and model serving—in our approach to the ML lifecycle.
In version 3.0 data scientists can now define the data processing graph. The graph can be comprised of different blocks, such as data transformation tasks, validators, routers, model servers and even model ensembles.
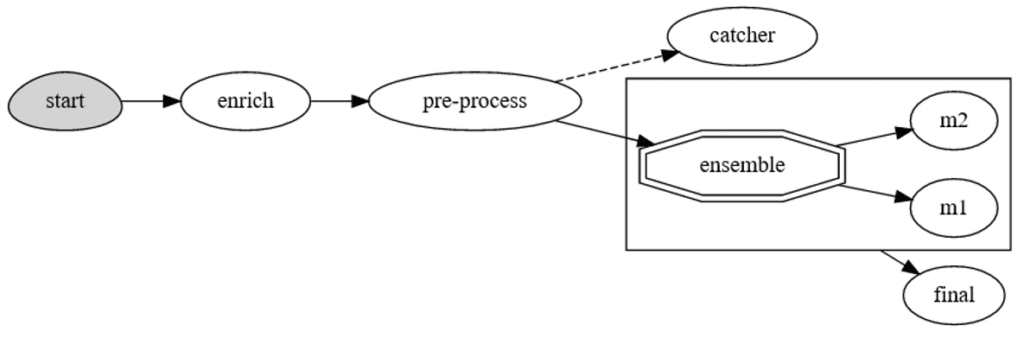
Graphs support real-time processing and therefore help maintain low-latency and high performance. It is also easy to test the graphs within your development environment, allowing you to test those pipelines prior to deployment.
Amazon Elastic Kubernetes Service and Usage-Based Pricing
Right from the start, the Iguazio Data Science Platform was designed to be deployed on VMs running Kubernetes. This enables lots of flexibility and the ability to truly deploy anywhere: cloud, on-prem, and even air-gapped networks. With the 3.0 update, you can now deploy on AWS Elastic Kubernetes Service (EKS). If you choose to as a managed service within the Iguazio Data Science Platform. Customers can now choose to deploy on an AWS managed Kubernetes service, which not only reduces the effort of managing the Kubernetes cluster itself, but also enables the ability to scale up and down the Kubernetes nodes.
Thanks to EKS, customers can now choose to pay only according to the actual compute resources consumed, with usage-based pricing . Of course, the fixed price option is still available, and you can even mix between fixed price for sustained load and usage-based price for peak loads.
Access from Anywhere
Remote cluster access is now supported in Iguazio 3.0. This means you can now launch any development environment and execute your code either locally or on the cluster, and you have lots of freedom to choose your tech stack with seamless integrations. For example, if you prefer to work locally, then use your favorite IDE locally (such as PyCharm and VS Code). If you would like to work from a cloud environment, you have the freedom to use solutions like Microsoft Azure ML Studio, AWS SageMaker, or GCP AI Platform and deploy to the cluster in a single command.
Skip Extra Legwork with New Support for Spark Operator and Updated Code Examples
With MLRun, Iguazio’s open-source MLOps orchestration framework, users can write the code once, and run the same code locally, or on different serverless runtime: Kubernetes job, Dask, Horovod or Spark. Many of the technical details are abstracted, allowing code to execute on different runtimes with very little configuration. This helps data scientists and data engineers focus on their implementation and not have to learn runtime-specific orchestration code.
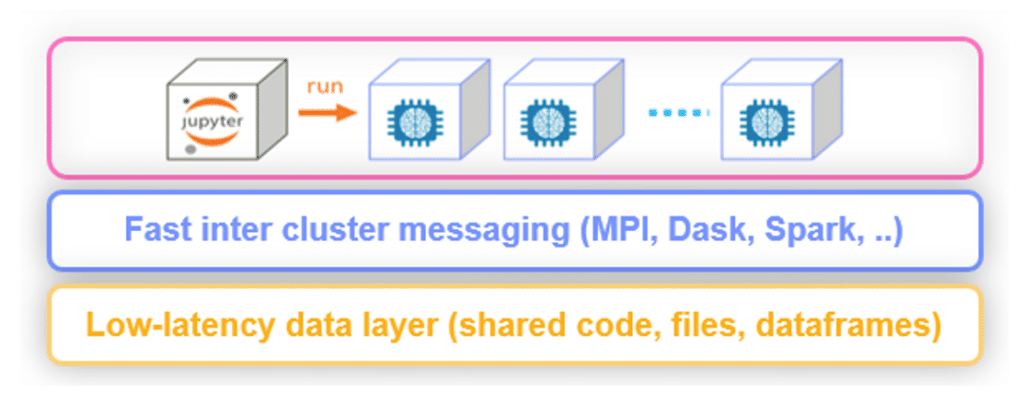
In this release, we have added support for Spark Operator runtime. MLRun ensures the Spark Operator request contains all the necessary configuration details to run. The Iguazio Data Science Platform includes the spark-operator service and therefore this runtime is supported out-of-the-box. We have also updated our examples for Dask and Horovod and we have ensured those distributed runtimes can scale up. This example code can be used as a convenient jumping-off point to reduce development time.
Improved Kubernetes Management
The Iguazio Data Science Platform embraces Kubernetes as a highly effective infrastructure component for machine learning development and deployment. However, keeping a Kubernetes cluster stable and managing the resource consumption can be tricky , especially when continuous operations is a showstopper. In this release, we have made some updates to ensure the stability of the Kubernetes cluster even in high loads. This means users can focus on building data pipelines and models rather than dealing with technical Kubernetes issues. The changes do not require additional administration on behalf of the user.
Restructured Documentation
We’ve updated so much to the platform over the past year, so our documentation needed a refresh as well. The new documentation portal has been reorganized: content is now divided into easily navigable high-level topics. Platform introduction and tutorials are in a more prominent location to help new users find what they need ASAP during onboarding. MLRun documentation is embedded within the Iguazio documentation, so everything now lives in a single location.
Hybrid Deployment with AWS Outposts
One of the key advantages of the Iguazio Data Science Platform is its ability to run anywhere: cloud, on-prem and even on air-gapped networks. AWS Outposts is yet another way you can choose to run your machine learning pipelines. AWS Outposts is a fully managed service that extends AWS infrastructure, AWS services, API and tools to virtually any datacenter, co-location space, or on premises facility for a truly consistent hybrid experience. The new seamless integration of Iguazio’s technology with AWS Outposts allows customers to build full blown, complex ML pipelines in weeks instead of months, with a lean team, and deploy them in hybrid environments while meeting all their performance, scale, and compliance needs.
Build ML models in any environment, such as Iguazio’s development environment or AWS SageMaker and deploy to their on-prem environment on AWS Outposts using the Iguazio Data Science Platform. This integration is especially important in cases where data resides (and remains) on-prem.
New Authentication Option
Use the OAuth2 (OIDC) authenticator to verify user identity when running serverless functions using the Nuclio API Gateway or accessing Grafana dashboards. Security administrators can define specific credentials to perform such access while limiting user access to other parts of the platform. With the OIDC authenticator, workflows can be executed via GitHub actions with read-only dashboards for specific users or groups.
New Data Node Type Availability
If you prefer to start with the smallest form-factor, you can now run the data nodes on AWS i3.2xlarge, saving you up to 30% on infrastructure costs. Manage the cost of your ML pipeline by increasing capacity only when business requires.
Summary
Version 3.0 is a huge leap forward in Iguazio’s offering for MLOps. It is now easier than ever to get your data pipelines and models to production, while ensuring that the deployments can scale and serve real-time events. With big plans for the year ahead, we’re focused on empowering ML practitioners to bring their most ambitious data science initiatives to life.


