Cloud Data Services Sprawl … it’s Complicated
Yaron Haviv | September 14, 2016
Legacy data management didn’t offer the scalability one finds in Big Data or NoSQL, but life was simple. You’d buy storage from your vendor of choice, add a database on top and use it for all your workloads.
In the new world, however, there are data services for every application workload. Targeted services may sound great, but multiple workloads mean complex data pipelines, multiple data copies across different repositories and complex data movement and ETL (Extract, Transform, Load) processes.
With single-purpose data silos, the cost of storage and computation grows quickly. Companies like Amazon or Google have jumped in, selling targeted services – raking in lots of money, at higher margins and often with tricky pricing schemes.
It’s all very complicated. But now it’s time for enterprises to demand unified data services that have better API variety and a combination of volume and velocity. There’s no need for so many duplicated copies, for such complex data pipelines or for ETLs.
AWS as a Case Study
Amazon Web Services (AWS) offers 10 or more data services. Each service is optimized for a specific access pattern and data “temperature” (see Figure 1 below). Each service has different (proprietary) APIs, and different pricing schemes based on capacity, number and type of requests, throughput, and more.
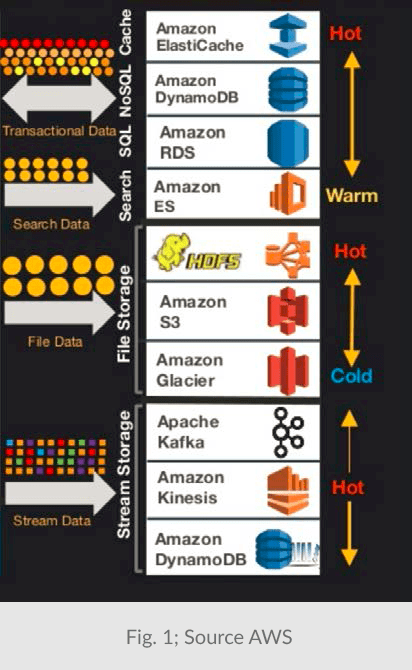
In most applications, data may be accessed through several patterns. For example, it may be written as a stream but read as a file by Hadoop or as a table by Spark. Or, perhaps individual items are updated while the list of modifications are viewed as a stream. The common practice is to store data in multiple repositories or move them from one to another as illustrated in figure 2.
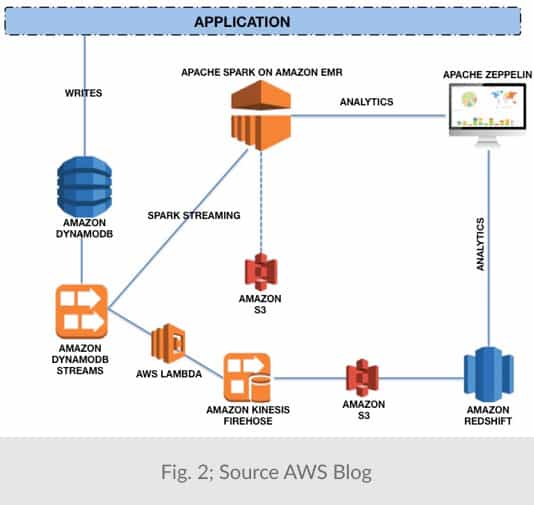
Fig. 2 shows six services (DynamoDB, DynamoDB Streams, S3, Lambda Redshift and Kinesis) being used to move and store the SAME data. With each service acting as a one-trick pony, the application consumes far more capacity and processing than if there were a holistic service that supports multiple workload types.
The pipeline approach used by AWS and others has major drawbacks beyond complexity. For example, it is very difficult to track data security and lineage when the data wanders between different stages because context or identities can get lost in translation. Long pipelines also mean results are delayed quite a bit since they need to traverse multiple stages until they are analyzed.
The chart below may help guide in deciding which service is right for each potential job:
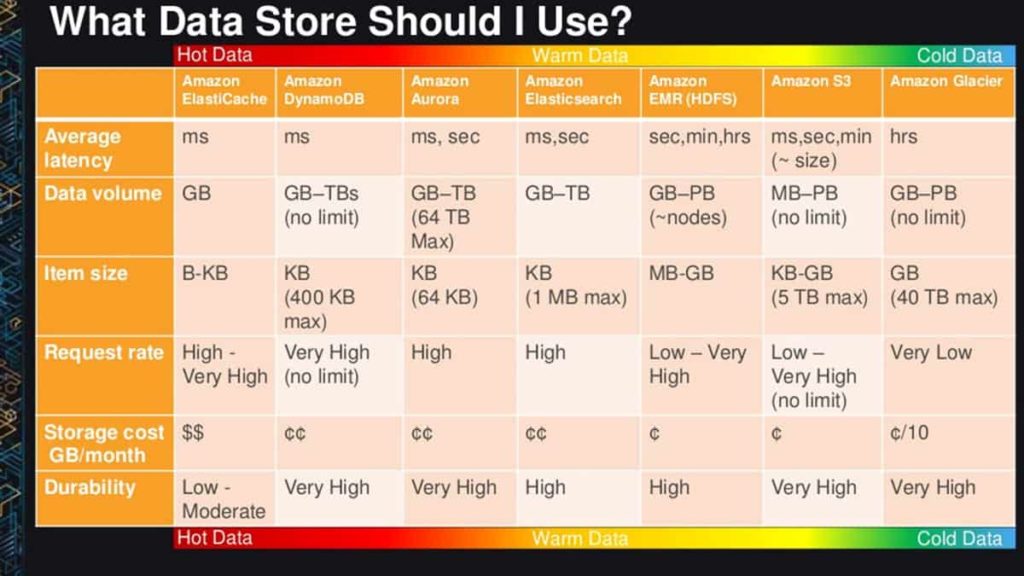

Wrong choices are costly
For applications that need to store medium-sized objects, choices might include both S3 and DynamoDB. T the intuitive decision is to take S3 because it’s “simpler and cheaper”). Simple? … Not really.
Let’s run through the math with couple of use cases:
| Object Size | Writes/Sec | Reads/Sec | Total Capacity | |
| Case 1 | 2KB | 500 | 500 | 10 TB |
| Case 2 | 64KB | 50 | 50 | 10 TB |
Using the AWS Price Calculator, the results show that for Case 1 it is clearly less costly to use DynamoDB, while for Case 2 S3 is cheaper.
What that shows is that even with a low transfer rate(less than 1,000 requests per second) the S3 IO and bandwidth costs far outweigh the commonly referred to S3 capacity costs (of 3 cents per GB).
| s3 | DynamoDB | |||
| Case 1 | Case 2 | Case 1 | Case 2 | |
| Capacity Cost | 302 | 302 | 2,679 | 2,557 |
| Requests Cost | 7,020 | 702 | 497 | 799 |
| Transfer Out Cost | 230 | 782 | 230 | 782 |
| Total Cost | 7,552 | 1,786 | 3,406 | 4,138 |
| $/GB per month | 0.76 | 0.18 | 0.34 | 0.41 |
Note that for a company using DynamoDB with 20K Requests/sec and 10TB of data (with zero transfer-out), -- something all NoSQL solutions can fit into a single mainstream server node – the company would pay AWS $172,000 per year (or more than half a million dollars in 3 years, the average life of a server). Imagine how many on-prem servers the company could purchase for that amount.
Summary
It’s time for simplification; it’s time to use smarter virtualized data services platform that can address the different forms of data (streams, files, objects and records), map them all to a common data model that can read and write data consistently, regardless of the API used.
With the latest advancement and commoditization in high-performance storage, such as fast flash and non-volatile memory, there’s no need for separate products for “hot” and “cold” data. Tiering logic should be implemented at the data service level rather than forcing application developers to code to different APIs.
By unifying and virtualizing data services over a common platform we save costs, reduce complexity, improve security, shorten project deployment time, and shorten time to insights (from the second the data arrives until it is mined for analytics).
www.iguaz.io is the first to deliver high-performance data platform with a unified data model and is positioned to disrupt the market, others will surely follow.


