How to Bring Breakthrough Performance and Productivity To AI/ML Projects
Yaron Haviv | October 25, 2021
By Jean-Baptiste Thomas, Pure Storage & Yaron Haviv, Co-Founder & CTO of Iguazio
You trained and built models using interactive tools over data samples, and are now working on building an application around them to bring tangible value to the business. However, a year later, you find that you have spent an endless amount time and resources, but your application is still not fully operational, or isn’t performing as well as it did in the lab. Don’t worry, you are not alone. According to industry analysts, that’s the case in more than 85% of AI (artificial intelligence) deployments.
Moving from research (using small data sets) to robust online production environments is far from trivial. Production environments need to process large amounts of real-world data and meet application performance and SLA goals. The move from lab to production involves multiple practitioners across teams (data scientists, data engineers, software, DevOps, SecOps etc.) who need to work in synchronization to build production-grade AI applications.
In order to effectively bring data science to production, enterprises need to change their mindset.
Most organizations today initially focus on research and model development because that is often seen as the natural first step to the data science process. However, taking a production-first approach is a sign of operational maturity and strategic thinking. Enterprises that take a production-first approach can plan for the future and make sure to harness the tooling to support the data science process as they mature and later scale. To industrialize AI, an ML (machine learning) solution that delivers scalable production grade AI/ML applications is needed. One that streamlines the workflow and fosters collaboration across teams, with a focus on automation to improve productivity.
One option is to build an AI solution from discrete open-source tools, infrastructure components, and/or cloud services, but that requires significant amount of IT and engineering resources. Another option is to choose a pre-integrated and managed solution which lets you focus on solving your business problem, instead of data wrangling, resulting in a higher level of productivity and better performance.
Adopting a production-first mindset, and the tools to support it
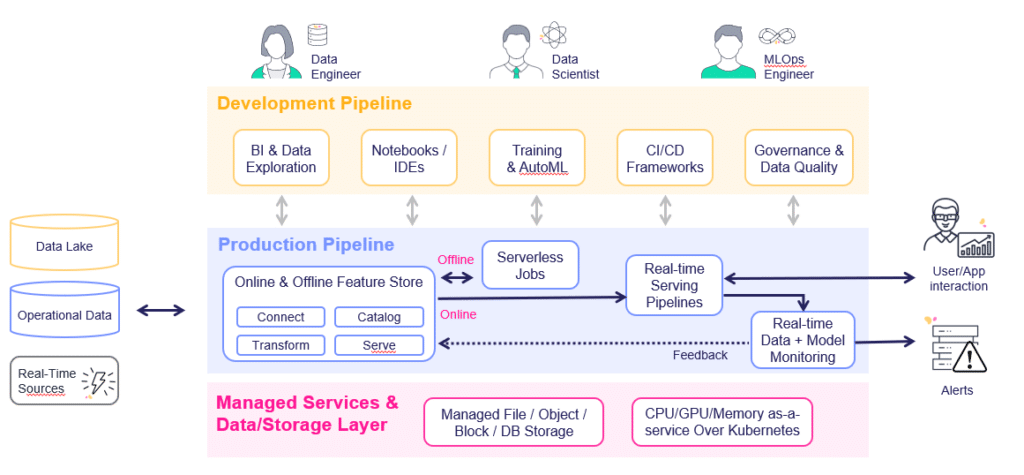
In order to effectively scale AI, enterprises need to adopt a production-first approach, and consider production as early as possible in the data science process. Ideally you should start by defining the production pipeline, then consider the required infrastructure, development tools and practices needed to support this pipeline, then begin developing your models when you’ve already thought of – and accounted for – what you will need in production.
Then, once you are ready to add additional pipelines and scale your data science practice, you’ll have the building blocks in place to do so effectively and efficiently. A naïve architecture will make it harder and harder to support diverse and growing business needs. As the organization scales, what matters most is the marginal cost of adding more pipelines. With the right architecture, that cost is relatively flat since it's mostly abstracted by the system.
AI/ML Production environments have 4 main components:
- Data acquisition and feature engineering: bringing data from offline or live online sources and transforming it to meaningful and usable data, then registering it for use in training and serving
- Scalable data repository: an enterprise-grade, high-performance shared data store for efficient hosting of both structured and unstructured data
- Training pipelines: taking a snapshot from the production data, training and testing models that will be used in production
- Serving pipeline: getting user requests or events, processing them, enriching them with additional pre-calculated features, applying AI/ML logic and responding or issuing actions
- Data and model monitoring: monitoring the production data quality and model behavior to detect anomalies, issues with accuracy, detecting drift and triggering alerts or corrective actions (like re-training a model)
The components used in the production environment are developed and tested with a variety of tools, like interactive data exploration tools, notebooks, IDEs (eg. PyCharm or vscode), model training frameworks or services, Git, CI/CD (continuous integration/continuous deployment) and automation tools, etc. It is critical that every component developed is tested at scale and deployed automatically without the need to refactor the code or go through a series of manual and labor-intensive tasks which will lead to significant unnecessary effort and long delays.
In order to achieve this goal, enterprises need to adopt a few guiding principles:
- Foster collaboration across data science, engineering and DevOps teams by adopting the same practices and the same toolset across these teams
- Reuse the same code base for research, small scale testing and production deployments, perform incremental changes and avoid re-implementation
- Focus on automation across development and deployment
- Use scalable enterprise-grade infrastructure to host data and compute across development and production environments
These goals can be achieved with a cloud-native approach, where Kubernetes, containers and shared storage serve as the common infrastructure, with a set of managed services on top which address the different elements in the development and project lifecycle management.
One of the ways to significantly reduce development and deployment overhead is by adopting serverless technologies which convert simple code to scalable, hardened, and managed micro-services.
MLOps (machine learning operations) orchestration frameworks based on serverless technologies can automatically convert code to serverless engines addressing different types of workloads (batch jobs, real-time Nuclio functions, Dask, Spark, Horovod, etc.)
MLOps platforms should provide end-to-end automation. With a feature store, features can be generated and shared across teams and projects. Batch and real-time pipeline orchestration, model serving, model monitoring and re-training logic together all save valuable time and accelerate the data science process.
The underlying infrastructure should be built for scale and high performance, support structured and unstructured data, and be enterprise-grade for utmost security. Reliable and scalable infrastructure to handle massive amounts of data and computation for real-world data science projects.
Bring your Data Science to Production with Pure & Iguazio
Iguazio is an MLOps platform that automates and accelerates the path to production.
Its serverless and managed services approach shifts the focus from coping with a sprawl of Kubernetes resources to delivering a set of higher-level MLOps services, over elastic resources, therefore reducing significant capital and operational costs, and accelerating time to market.
Iguazio includes a central portal, UI, CLI, and SDK to manage the entire MLOps workflow with minimal integration efforts.
However, this cannot work without a high-performance, scalable, and robust storage layer underneath. Data science projects depend on processing large amounts of structured and unstructured data in short times, and data access must be secure and highly available.
Pure storage products are optimal for the challenges of data science, providing speed and simplicity at scale. Unstructured data can be organized in files or objects (on Pure FlashBlade) and accessed directly by the applications. Iguazio’s real-time feature store can access structured data on high-performance, low-latency NVMe storage using Pure FlashArray. Pure Portworx native Kubernetes storage can be used to support the persistency needs of different stateful micro-services.
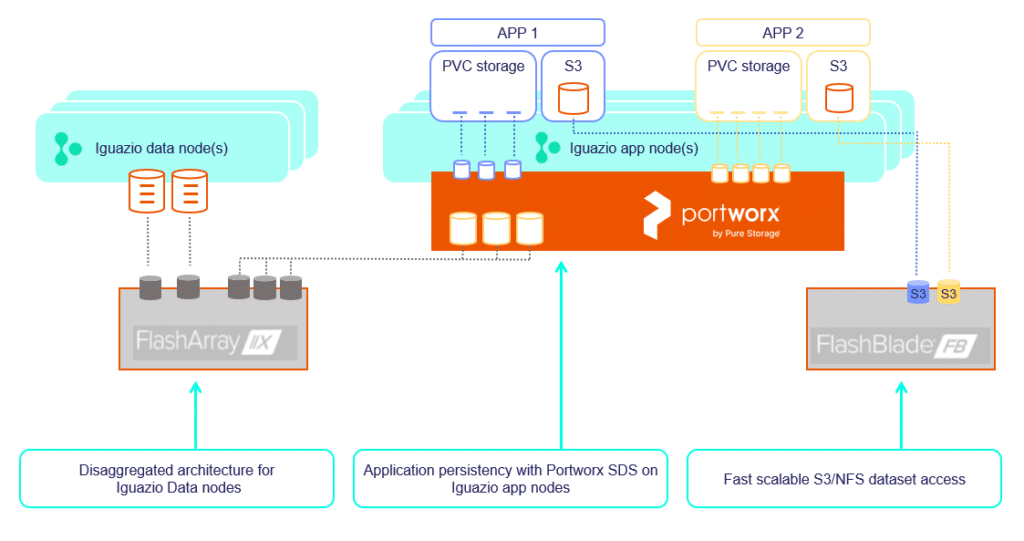
Iguazio with Pure Storage
Using the joint Pure-Iguazio solution, enterprises can:
- Implement an automated, scalable and performant enterprise grade MLOps platform
- Gain an agile ML solution where compute and/or storage scale as your ML needs evolve
- Reduce the overall storage footprint by an order of magnitude (by leveraging Pure compression and deduplication technology)
- Provide enterprise-class storage features (snapshots, backups, sync, encryption, etc.)
Pure and Iguazio have joined forces to help enterprises unlock the value of their data and bring data science projects to life in an efficient, automated and repeatable way. Together, they empower enterprises to continuously roll out new AI services, focusing on their business applications and not the underlying infrastructure.
To see the solution for yourself, contact us to book a live demo



