Predictive Real-Time Operational ML Pipeline: Fighting First-Day Churn
Yaron Segev | November 24, 2020
Retaining customers is more important for survival than ever. For businesses that rely on very high user volume, like mobile apps, video streaming, social media, e-commerce and gaming, fighting churn is an existential challenge. Data scientists are leading the fight to convert and retain high LTV (lifetime value) users.
Fighting First-Day Churn with Real-Time Data
Consumers have round-the-clock access to infinite innovative products and services, and brands must work continually to keep users engaged. The challenge is to maximize the likelihood that people will stick around and use more of the product, and minimize the probability that they’ll quit. User acquisition is expensive: it’s five times cheaper to retain an existing user than to acquire a new one, and an existing customer is three times likelier to convert than a new one. Overall a 5% increase in customer retention can increase profits by 25% to 125%.
This is where data science can be a critical ingredient for retention strategy. By processing data from multiple sources, a machine learning model can identify patterns and predict churn before it happens. Algorithms can identify patterns that can’t be detected with human cognition. Once a pattern has been detected, brands can take smart actions in real time—like offering a coupon, or directing them to more engaging content, or another reward—to ensure that users find continued success from day one.
Most churn prediction algorithms are based on ensembles with a Survival algorithm that predicts when the “about to churn” moment is about to occur, triggering the right reward at the right moment. Then, users are classified per their pLTV (predictive lifetime value), and the appropriate action policy (e.g. reward level) is applied.
Using the abundance of data generated by customers’ online behavior, the process of creating a model, testing and validating is relatively straightforward.
From the Lab to a Business Growth Engine
The science of analysis and real-time AI decision-making is just the beginning of the fight against churn.
Real-Time Considerations
- The model is just one part of a larger pipeline. It’s critical to address the speed at which the data is delivered to the model. The overall latency must meet the requirements of the use case. Typically, it takes a first-time user a few minutes to get to the “about to churn” moment, and other user patterns can happen much faster.
- To address 1st day or 1st session churn, ML based actions typically need to be triggered within the first minute, and continually sample user behavior in real time
- Models commonly rely on aggregation features and identifying sequence of events, in order to detect patterns. Aggregations must be calculated quickly.
In the lab: During training in the lab, ML model features are mostly calculated based on files and databases and in a batch mode, minimizing data volume by using sample data. The model build process can take hours or even days.
In real-life: Your real-time operational ML pipeline needs to be built for events arriving in ultra-high velocity and high volume, as well as being calculated and triggering action in a minute or less.
Building for both: ML feature calculations must be done correctly in both scenarios. It’s not easy to write code that can handle both, yet writing different code for lab training and real life prediction is a massive duplication of effort.
Constant change: User behavior can change in an instant. Previously accurate models can fail when new trends emerge and behavior patterns change. Once this concept drift occurs, models need to be retrained and deployed quickly, or else they lose their value.
Data Science is a Team Sport
With all these challenges, data scientists often find themselves dealing with technical aspects that are outside their domain. This process can easily take months to complete, and usually requires significant coordination with software engineers and production deployment teams. Despite their significant growth opportunities, these projects can stall, as they wait to be prioritized by business leaders. While they wait to move forward on these projects, enterprises leave potential revenue on the table, or expose the business to high risk.
The New Way to Develop and Deploy AI
At Iguazio, we believe that data scientists should focus on data science and experience a frictionless transition from the lab to production. We also believe that enterprises need a way to quickly derive business value from their machine learning models and leverage their opportunities.
That’s why we developed a data science platform that enables rapid deployment of a real-time operational machine learning pipeline at scale, enabling complete lab to production in weeks, with a lean team.
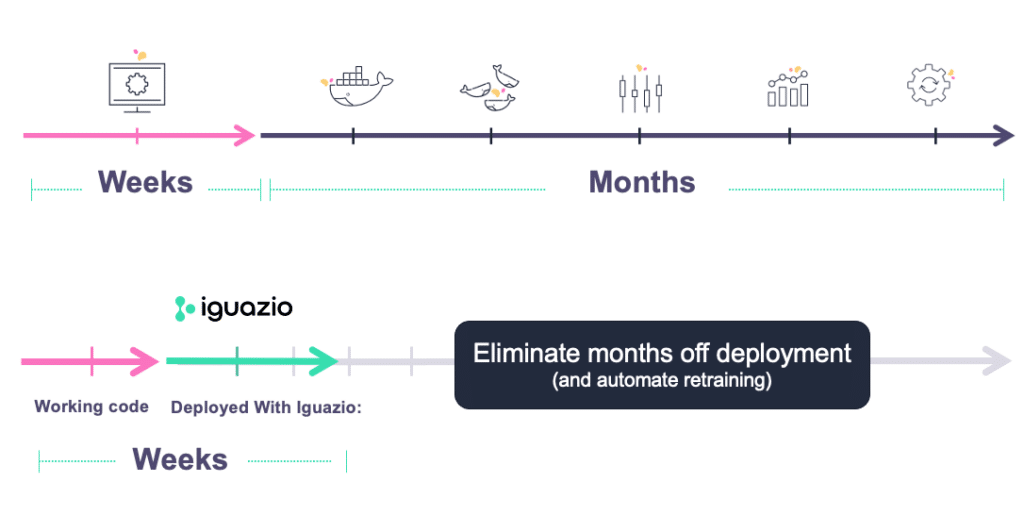
Strategies for Rapid Deployment of AI
Feature engineering: The data scientist writes Python code and Python frameworks to develop the model features. The code is written once, and executed in both the training batch environment and the online real-time environment. Iguazio converts the Python functions to highly scalable low-latency serverless functions.
One-click notebook to microservice: The data scientist uses Jupyter notebooks to write their code, just like the features. The notebook is then converted to highly scalable serverless code.
Automated pipeline: The entire process is orchestrated by defining a pipeline. This pipeline enables automatic execution of all those serverless functions, easy monitoring of the execution status and identifying concept drift.
Rapid Deployment Template
We worked with our customers to create a ready-made template for quick deployment of a fully operational pipeline. This “Real Time Operation Pipeline Template” is highly customizable with your data inputs, models and outputs, and is elastic that easily scales.
Typically, large volume, high velocity projects require one data scientist and one data engineer. Adapting the template to your use case takes less than a week. Everything is done for you using this framework—including latency and scale considerations—with no need to involve DevOps.
The Operational Pipeline Flow
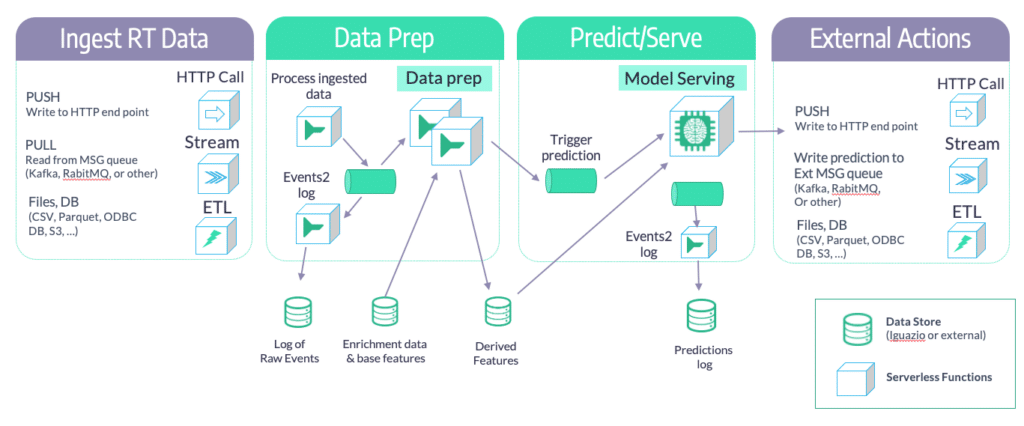
Real-Time ML Pipelines for Additional Use Cases
Beyond 1st-day churn use cases, the same template can be applied to other situations where real time is a critical factor, like:
- Fraud prevention: With real-time processing, financial companies can move from fraud detection to fraud prevention. Stop fraud before it happens, while ensuring normal business operations continue with minimal false positive. This means a quick classification of fraud / not-fraud (or: human intervention). All is recorded, monitored and can be easily audited.
- Regulatory requirements: Some industries must abide by regulations and laws that require them to react quickly, like financial services, healthcare and some segments of online gaming. These regulations may impose strict limits on the amount of time a service provider has to identify problems and take actions. Failure to comply may result in significant fines or expose the business to legal action.


