A machine learning (ML) model pipeline or system is a technical infrastructure used to automatically manage ML processes.
While the ML lifecycle spans everything from data collection to model monitoring, we will focus in this article on the serving infrastructure only.
Machine learning model serving involves providing predictions on new data points by performing inference on a trained model.
When inference is performed on more data points without the need for immediate results, it is referred to as “batch serving” or “offline serving.” These batch jobs are typically run on a recurring schedule.
When inference is performed on one single data point and expects an instantaneous prediction, it is referred to as “real-time serving” or “online serving.” These requests are typically served through an API but can also be run directly on mobile devices, IoT devices, and browsers::
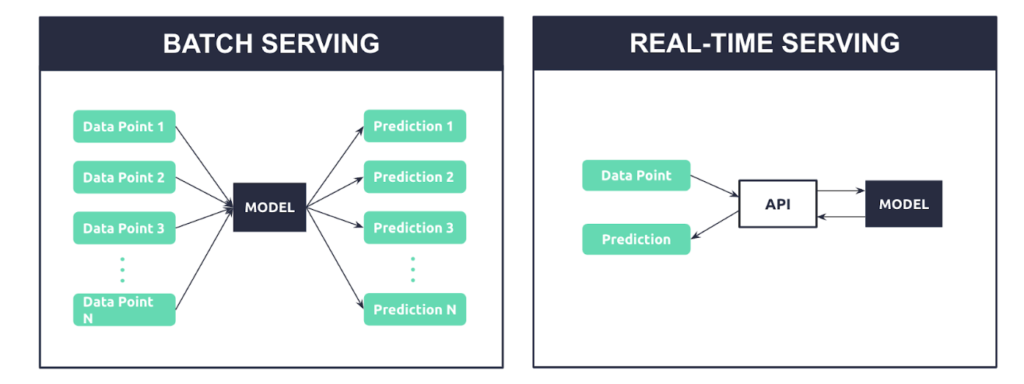
Figure 1: A simplified diagram view of batch serving and online serving
Generally, practitioners think of real-time model serving with REST APIs when talking about model serving pipelines. We will follow this convention for the rest of the article.
The diagram above shows a simplified view of serving. In practice, model serving is more complex than “just” serving a model as an API:
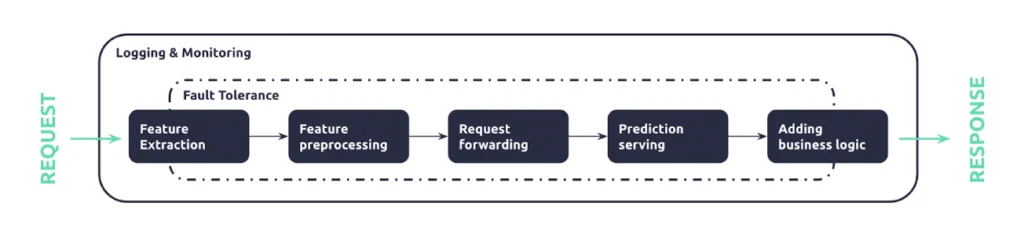
Figure 2: A high-level view of a serving infrastructure
As seen in Figure 2, serving machine learning models require:
Additionally, the complexity of a serving infrastructure can grow over time as the number of features, number and patterns of requests, number of automated processes such as triggered retrainings, and the number of models in production change.
When hosting multiple models in production for the same application, the two most common approaches are multi-armed bandit model serving and ensemble models. Multi-armed bandit is a state-of-the-art model serving solution where multiple models provide a prediction in parallel, and the traffic is dynamically and automatically routed by a reinforcement learning agent to the models that perform the best. On the other hand, ensemble models are a solution where the prediction of multiple models is combined to provide the final one.
With such a system, it is easy to see how defining an automated pipeline is fundamental for you to manage an end-to-end serving infrastructure in a reliable and standardized way.
In the previous section, we introduced the steps required to build an ML model serving pipeline. Now, we’ll be taking a deep dive into each to understand the main considerations and goals when building a model serving architecture.
A request does not typically contain all the features needed for inference. These missing features must be retrieved from a feature store to match the same feature set used at training time. This is fundamental to ensure the correct model performance.
A modern feature store provides feature extraction capabilities that allow for minimum latency and maximum recency, while also providing desirable abilities including data discoverability and lineage. More information on feature stores can be found here.
Similar to the previous step, the same data transformations performed at training time must be mirrored at inference time to ensure the correct model performance. This preprocessing often involves transforming features derived from the request itself or defining default values when missing.
Note that some ML model frameworks such as TensorFlow and Scikit-learn allow you to embed the data-preprocessing respectively as a layer to the model or as a chained model, in which case this step is a part of prediction serving.
A load balancer can be set up to handle request forwarding when high availability is required or when multiple models are served. The configuration is specified via forwarding rules.
One or more models are wrapped into applications deployed as containerized microservices to allow for scalability, reproducibility, and ease of deployment. Note that any of the steps above can be deployed as a containerized microservice. More information on what tools to use for application building can be found in the “What Are the Most Common Model Serving Frameworks?” section below.
Notwithstanding the specific framework used, an application takes the preprocessed feature input and returns a prediction response to the user by calling a predict method on the model loaded in memory at application startup. The output of the model prediction is most commonly a score of between 0 and 1 defining each class’ likelihood of being correct for classification, or a number for regression.
Often, before returning the response, the application processes the model output into a more relevant format for the user and the business. Business logic rules typically aim to optimize for diversity, freshness, and fairness.
Real-time applications are critical, and teams and users must be able to rely on them to always be available. When deploying a model serving pipeline, zero downtime can be guaranteed by using DevOps best practices to provide automated scaling, replication, sanity checks, canary deployments, and more. We recommended looking at Kubernetes for model serving.
Finally, logging and monitoring are the tools that let you track if the pipeline is functioning correctly and be alerted if otherwise.
Developing a model serving pipeline that is consistent and reliable is expected to be a long-term endeavor for an ML engineering team. Instead, we recommend considering a complete MLOps offering such as Iguazio, which provides model deployment with Nuclio as well as support for an end-to-end ML lifecycle.
At a high level, model serving frameworks can be divided into general REST API wrappers, like FastAPI and Flask, or ML-specific serving tools.
The latter are Kubernetes-based solutions that are either self-hosted, such as KFServing and BentoML, or managed, like Seldon Core, AWS SageMaker, and Nuclio.
A REST API toolkit can be a good option because it is a well-known standard for engineering teams, but it is not ML-optimized and requires a lot of extra code on top to cover the needs of a serving infrastructure.
ML-specific frameworks are recommended, with the self-hosted and managed options sharing many similarities, as managed solutions are based on open-source toolkits like KFServing.
When selecting a tool, look for one that supports the end-to-end model serving pipeline while providing optimized performance and flexibility: Nuclio, included as part of a wider MLOps open-source framework called MLRun, allows for highly parallelized real-time processing with minimal hardware, I/O, and engineering overhead.