Machine learning (ML) is a broad discipline that encompasses a wide variety of techniques and algorithms. We can split the discipline into three subfields:
Supervised learning uses one of two techniques, regression or classification. While classification predicts a discrete class, such as dog versus cat, regression in machine learning predicts a continuous value, such as house prices.
This article presents an introduction to ML regression, a review of the most common associated evaluation metrics, a walk-through of when to use regression, and discussion of its most common types.
Regression, or regression analysis, is a statistical approach that aims to learn the relationship between independent variables, or “features”, and a dependent variable, also known as “target” or “label”. Once this relationship is learned, the regression model can be used to predict the target for unseen samples.
Like all statistical approaches, regression is based on data. The trained regression model will only be as good as the data from which it learns. To minimize complexity and maximize performance for model training, we need to make sure that certain conditions are met:
During model training of a regression approach, the relationship in the data is learned by finding the line of best fit based on all available data points.
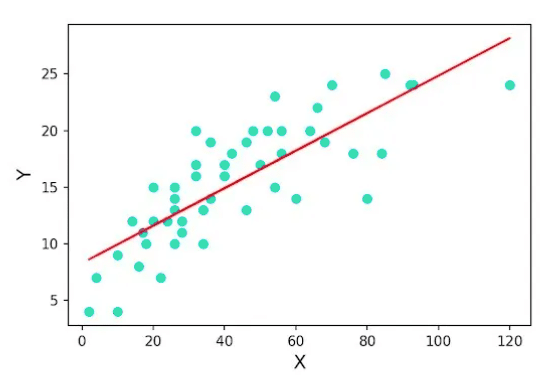
Figure 1: A sample regression line that best fits the available data points
The regression line shown above (Figure 1) depicts the simplest type of regression, wherein a straight line is learned. This is referred to as linear regression.
This might remind you of the linear equations that you studied back in Algebra 101. Learning the best fit line in linear regression and solving a linear equation are indeed similar processes, but with one important difference: whereas in a linear equation variables appear in a linear fashion, in a linear regression coefficients appear in a linear fashion.
The formula for linear regression is:
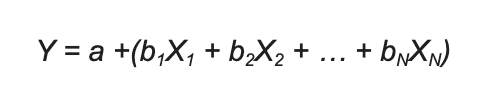
N is the number of available features.
When N=1, we are fitting a line like in the plot above; with N>1, we are still fitting a “line” but in a multi-dimensional space, with one dimensional space for each input Xi feature.
The regression algorithm learns—i.e., adjusts—the coefficients during multiple iterations of model training. It does so by selecting iteratively the combination that optimizes the cost function, that is, the combination that minimizes the prediction error. This ensures that the resulting line best fits the data within an accuracy reported by the chosen regression metrics.
Regression metrics are a measure of the distance—i.e., error—between the fitted line and each data point. The lower any of these errors, the better the machine learning regression model has learned the data, and the more accurately it can predict when fed new data samples.
Let’s take a look at the three most commonly used regression metrics.
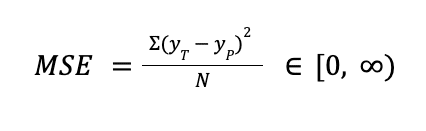
MSE is the average squared difference between real and predicted labels.
It is typical to choose MSE when we want to penalize heavily larger errors.
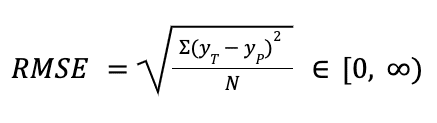
RMSE is the square root of the average squared difference between real and predicted labels. In other words, it is the standard deviation of the prediction errors.
Choosing RMSE makes sense when we want to penalize larger errors to a moderate extent, while keeping the same units as the dependent variable.
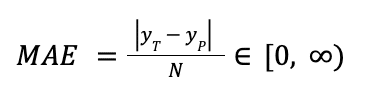
MAE is the average absolute difference between real and predicted labels. The absolute operation is non-differentiable, which makes the mathematical operation more complex than for the previous metrics.
MAE is the appropriate choice when we want to give the same weight to all individual errors while keeping the same units as the dependent variable.
Regression is one of the most common ML approaches. Whenever we are predicting a continuous variable, we are performing a regression prediction.
The most common applications of regression in ML are:
We see regression in use when looking at stock price prediction or weather prediction.
ML regression models—especially linear regression models—have the added bonus of being particularly easy to explain, given that the coefficients directly describe the effect of each feature on the predicted label. Making AI understandable to its many and diverse stakeholders is an important goal in itself as AI becomes increasingly mainstream.
Let’s take a look at the five most traditional types of regression analysis.
This algorithm performs predictive analysis by learning the linear relationship between data points and the target variable.
It’s worth noting here that logistic regression is actually a type of binary classification, not regression. This algorithm has been named as such because it first performs linear regression, and then maps the predicted continuous target to one of two classes via a threshold applied to the sigmoid function.
The polynomial regression algorithm performs predictive analysis by learning the non-linear relationship between data points and the target variable. When the polynomial regression equation has degree 1, it corresponds to linear regression. If its degree exceeds 1, the best fit line is a curve rather than a straight line.
This algorithm extends the polynomial regression approach by adding a small amount of bias, known as the ridge regression penalty or L2 penalty, to the loss. Its added regularization reduces the complexity of the model when there is high collinearity in the feature set.
Like ridge regression, lasso regression extends the polynomial regression approach by adding a small amount of bias to the loss. For lasso regression, this bias is known as the L1 penalty. This added regularization reduces the complexity of the model when there are a small number of relevant features in the feature set.
Regression can be performed on more than one target. This is called either multivariate regression or multi-output regression.
Most regression algorithms support multi-output regression either by extending the implementation to provide multiple outputs or by duplicating the model for each output in the problem.
Regression analysis techniques go further than the traditional techniques introduced above.
In fact, most implementations of supervised ML algorithms can be used for both classification and regression with minor modifications, such as decision trees and neural networks.
For real-world applications, it is common to adopt these more complex models and experiment on multiple regression algorithms simultaneously to find the optimal ML solution for the use case.
For regression as well as any other batch and real-time ML application, Iguazio offers a unified platform to bring end-to-end MLOps-driven data science to life with experiment tracking, feature store, monitoring, re-training, and CI/CD for ML. Iguazio integrates these capacities into a production-first approach that can lead your ML applications to success!





