Horovod for Deep Learning on a GPU Cluster
Adi Hirschtein | July 1, 2019
Here’s the problem: we are always under pressure to reduce the time it takes to develop a new model, while datasets only grow in size. Running a training job on a single node is pretty easy, but nobody wants to wait hours and then run it again, only to realize that it wasn’t right to begin with.
The solution is where Horovod comes in - an open source distributed training framework which supports TensorFlow, Keras, PyTorch and MXNet. Horovod makes distributed deep learning fast and easy to use via ring-allreduce and requires only a few lines of modification to user code. It's an easy way to run training jobs on a distributed cluster with minimal code changes, as fast as possible.
The main benefits in Horovod are (a) the minimal modification required to run code; and (b) the speed in which it enables jobs to run.
We’ll use a Keras example in this post.
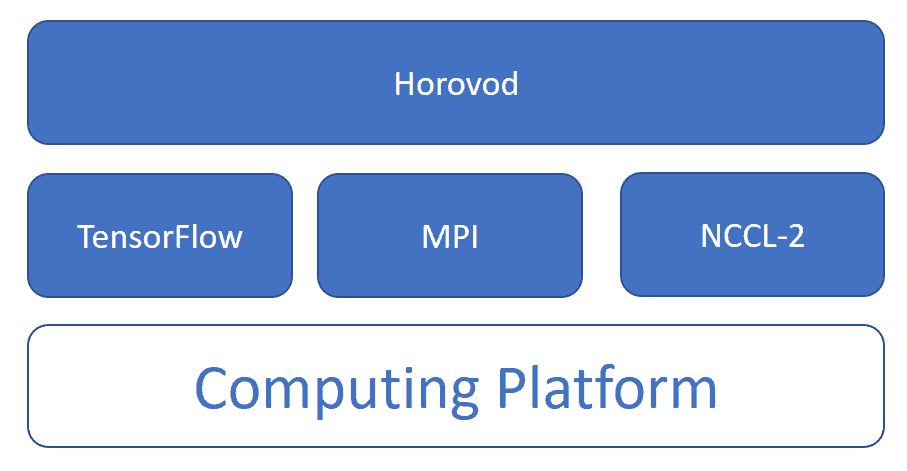
Horovod is installed using pip and it requires the prior installation of Open MPI and NVIDIA’s NCCL - two libraries which support inter-GPU communication. A Data Science Platform such as Iguazio offers them already deployed.
Woof vs. Meow
Here's an example that demonstrates how to use Horovod to take an existing training job and run it as a distributed job over several GPUs. We used an existing image classification demo for image recognition. The demo application builds and trains an ML model that identifies (recognizes) and classifies images:
- Data is collected by downloading images of dogs and cats from an Iguazio sample dataset AWS bucket.
- Training data for the ML model is prepared by using Pandas DataFrames to build a prediction map. Data is visualized by using the Matplotlib Python library.
- An image recognition and classification ML model that identifies the animal type is built and trained by using Keras, TensorFlow, and scikit-learn (a.k.a. sklearn).
Before running the job, the first phase is to bring data in and prepare it for training. We don't cover this prep work here, but more info about it is available in Iguazio’s V3iO Github repository.
We change the training code itself to use Horovod once the data is prepared. The code below includes references to the section we had to adjust in order to run it with Horovod.
Cats and Dogs - Image Recognition Code
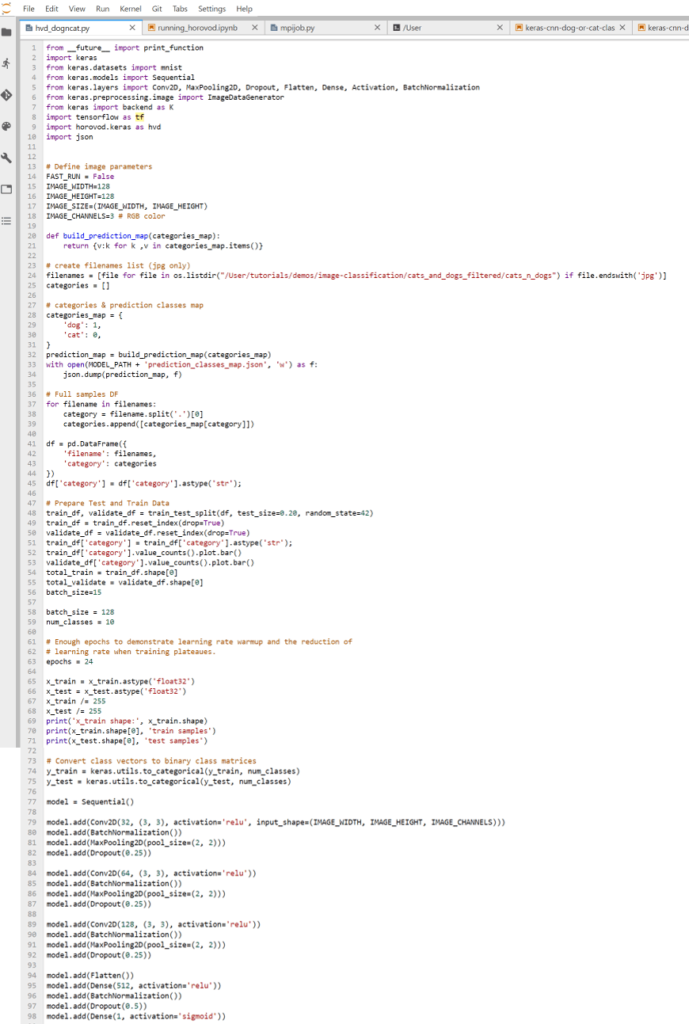
Code changes Required to Run Horovod:
- Initializing Horovod: hvd.init()
- Pin GPU: pin a server GPU to be used by this process with config.gpu_options.visible_device_list. This can be set to local rank with the typical setup of one GPU per process, which means the first GPU is allocated to the first process on the server; second process allocated to the second GPU; and so forth.
- Adjust learning rate based on the GPU number: scale the learning rate by number of workers. Effective batch size in synchronous distributed training is scaled by the number of workers. An increase in learning rate compensates for the increased batch size.
- Add Horovod distributed optimizer: wrap optimizer in hvd.DistributedOptimizer. The distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients.
- Add callbacks: add hvd.BroadcastGlobalVariablesHook(0) to broadcast initial variable states from rank 0 to all other processes. This is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint.
![]()
Running the Job
Now, let’s run it from Jupyter. Note that users can control the number of GPUs and workers for the job. In this case we’ll run it on a DGX machine with 8 GPUs. Each replica uses one GPU. In order to run the job, the user needs to specify the image location and the actual Python code (as seen above).
![]()

Monitoring the Job
Once the job is running we should be able to see number of pods as the number of workers and track their status. Note that when the job is launched, Horovod opens up a launcher job as well. Logs are accessed through the launcher pod.
![]()
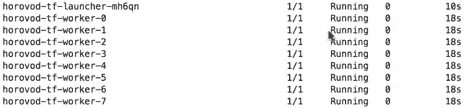
In addition we can leverage NVIDIA library (nvidia-smi) to get real-time GPU stats:
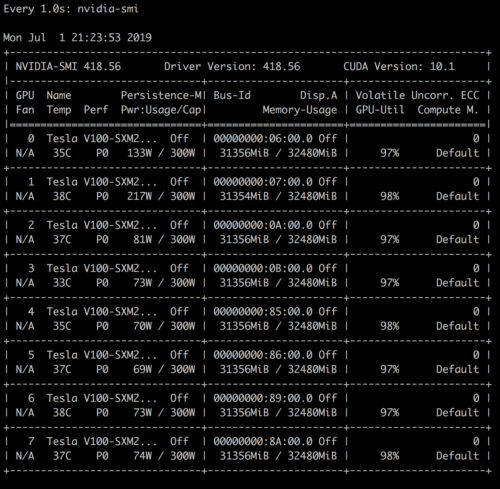
Note that Horovod immediately frees the GPU resources when the job is done.
Conclusion
We’ve demonstrated how to convert an existing deep learning training job into a distributed job using Horovod with minimal code changes, and then monitor it while it’s running. We also covered devops as Horovod requires library deployment in order to make it ready for a data scientist to easily consume. Data Science Platforms such as Iguazio already have those libraries ready and therefore do not require additional devops - so that data scientists can focus on converting their code.
This post was written with contribution from Iguazio Big Data Team Leader, Golan Shatz and Iguazio Data Scientist, Or Zilberman.


