MLRun is the first open-source AI orchestration framework for managing ML and generative AI application lifecycles. It automates data preparation, model tuning, customization, validation and optimization of ML models and LLMs over elastic resources. MLRun enables the rapid deployment of scalable real-time serving and application pipelines, while providing built-in observability and flexible deployment options, supporting multi-cloud, hybrid and on-prem environments.
Github | Join the Slack Community

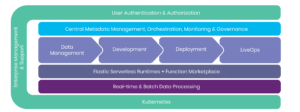
of code to production pipelines
for batch and real-time workloads

with real-time serving and application pipelines

in your local IDE, multi-cloud or on-prem
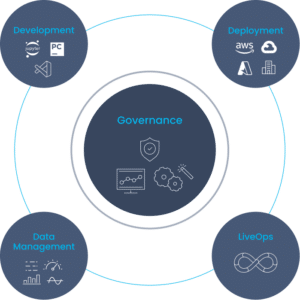

Operators can painlessly set up the system through wizards, configure administration policies and register for system notifications, with no need for automation scripts or hands-on daily management. The Iguazio Data Science Platform with managed MLRun is delivered as an integrated offering with enterprise resiliency and functionality in mind. Enable data collaboration and governance across apps and business units without compromising security or performance. Authenticate and authorize users with LDAP integration and secure collaboration. The real-time data layer classifies data transactions with a built-in, data firewall that provides fine-grained policies to control access, service levels, multi-tenancy and data life cycles. Enterprise customers get dedicated 24/7 support to onboard, guide, and consult.
Lift the weight of infrastructure management by leveraging built-in managed services for data analysis, ML/AI frameworks, development tools, dashboards, security and auth services, and logging. With managed MLRun, anyone on your ML team can simply choose a service, specify params and click deploy. Data scientists can work from Jupyter Notebooks or any other IDE and automatically turn it into an elastic and fully managed service directly from Jupyter or another IDE, with a single line of code.




















