The performance of a machine learning model degrades over time, absent intervention. This is why model monitoring is an important component of a production ML system. When a machine learning model’s predictions start to underperform, there can be several culprits.
After ruling out any data quality issues, the two usual suspects are data drift and concept drift. It’s important to understand the difference between them, because they require different approaches.
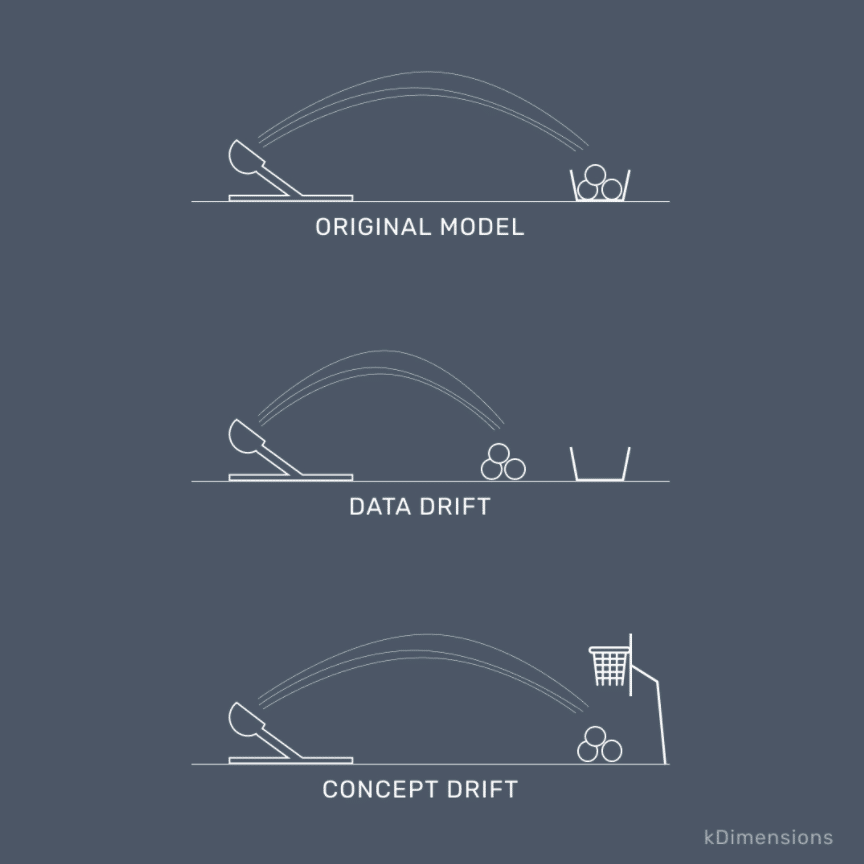
In data drift, the input has changed. The trained model is no longer relevant on the new data.
In concept drift the data distribution hasn't changed. Rather, the interaction between inputs and outputs is different than before. ֵIt practically means that what we are trying to predict has changed. A classic example is spam detection: over time, spammers try new tactics, so the spam filters need to be retrained to react to these new patterns.
For a deep dive on how to build a drift-aware production ML system, check out this blog.
For a super-simple explanation of these concepts, check out Meor Amer's brilliant illustration of this idea: